Introduction
CS846 Machine Learning for Software Engineering — Spring 2026
Pengyu Nie
Agenda
- Course logistics
- Round-table introductions
- ML/AI for SE research area overview
Course Logistics > Your Instructor

- Name: Pengyu Nie
- Assistant Prof @ UWaterloo CS since 2023
- before that: PhD @ UTAustin ECE
- before that: BSc @ USTC Physics
- 2nd time teaching this course
- Research interests on AI + SE, recent focus:
- AI-assisted test generation and maintenance
- Automating MLE (machine learning engineering)
- Efficient model architectures for SE
- … find out more in this course
Course Logistics > Communication
- The course website: https://pengyunie.github.io/cs846mlse-1265/
- Course logistics, syllabus, slides
- Email: pynie@uwaterloo.ca
- Project milestone submissions
- Announcements
- General questions
Course Logistics > Syllabus
- Week 1, 05/12
- Introduction and planning
- Week 2, 05/19
- Lecture: software engineering essentials (intro, program analyses, other artifacts, platforms & mining sources)
- Week 3, 05/26
- No class, please attend Kyunghyun Cho’s talk
- Week 4, 06/02
- Lecture: machine learning essentials (large language models, transformers, agents, etc.)
- Week 5, 06/09
- Project idea/proposal discussions
- Week 6 – Week 12: seminar/presentation (led by you), guest lectures, etc.
Course Logistics > Class Structure
Typical class structure starting from Week 6:
| Time | Item |
|---|---|
| 9:30-10:10 | Activity 1 |
| 10:10-10:20 | Break |
| 10:20-11:00 | Activity 2 |
| 11:00-11:10 | Break |
| 11:10-11:50 | Activity 3 |
- Possible activities:
- Guest lecture
- Seminar discussion on a topic (paper/report/blogpost/tool/demo/dataset/combination)
- Project presentation (around midterm: progress; around final: results)
- Propose other activities that you want to lead
Course Logistics > Assessment
| Task | Due Date | Weight |
|---|---|---|
| Participation | - | 40% |
| Project: team formation | 06/01 (Mon) | - |
| Project: proposal report | 06/12 (Fri) | 10% |
| Project: progress report | 07/10 (Fri) | 20% |
| Project: final report | 08/07 (Fri) | 30% |
Course Logistics > Assessment > Participation
- Each person should lead at least one activity during the term (seminar discussion, project presentation, etc.)
- You may co-lead (at most 2 people), but each co-leader should have non-trivial contribution;
- Time slots and/or topics are assigned at a first-come-first-serve basis; registration link will be provided later.
- You should also participate in the course activities (engage in discussions, ask questions, make comments, etc.).
- In-person participation is required; occasional absences (e.g., illness, conference travel) are allowed if communicated to the instructor in advance.
- I should be able to recall your name and face by the end of the term
Course Logistics > Assessment > Project
Team size
- 2–4 people recommended;
- 1 person: only if the project aligns with your thesis work & your research supervisor agrees;
- 5+ people: only if the project is well-designed and justifiable for a bigger team to run (expectations for project quality is higher).
Course Logistics > Assessment > Project
Project topic
- a short-paper-level (or above) project, example types of contributions:
- demo, tool: research prototype -> implementation & integration
- data: task -> dataset/benchmark
- mining challenge: dataset/benchmark -> statistics, analysis, findings
- replication: prior work -> results in updated context
- related to the course in some way, e.g., technique, dataset, application, ideology, etc.
- existing project welcomed
Course Logistics > Assessment > Project
Team formation by 06/01 (Mon)
- start finding teammates and discussing project ideas now
- the team lead should send an email to the instructor with all team members cc-ed
- if your team size is not 2–4, contact the instructor in advance to reach an agreement
Project idea/proposal discussions in class 06/09 (Feb)
- prepare a 3-minute pitch of your project idea
- collect feedback from the instructor and peers
Course Logistics > Assessment > Project
Milestones
- Proposal report by 06/12 (Fri): the abstract & introduction sections, outlining the motivation and proposed solution; ~1 page.
- Progress report by 07/10 (Fri): complete a couple of more sections of the paper, with some preliminary results and findings; 2–4 pages.
- Final report by 08/07 (Fri): the complete paper; 4–10 pages.
Course Logistics > AI Usage Policy
- Usage of AI assistants for coding and paper writing: Yes, but you are responsible for the quality of the work.
- do fact-checking, especially for the areas you are not familiar with;
- (coding) maintain good software engineering practices (test your code, follow coding conventions);
- (paper) use standard and professional terminologies, avoid hallucinated citations.
Round-Table Introductions
- Name
- Position (department, Masters/PhD, year)
- Research interests
- Expectations from this course
- One interesting fact about your hometown
ML/AI4SE Overview
I will…
- Present a brief history of the ML/AI4SE research area in the past decade or so. Disclaimer: this is my biased view constrained by my limited academic life.
- Give you some ideas of solved vs. unsolved research problems in the area.
- Motivate the next two lectures on SE and ML/AI essentials.
ML/AI4SE Overview > Naturalness of Software
Statistical (n-gram) language modeling of code
- Code written in PLs is natural: repetitive and predictable
- Code is more "natural" (lower cross-entropy) than English

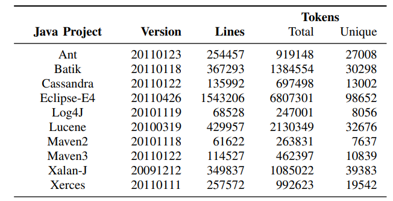
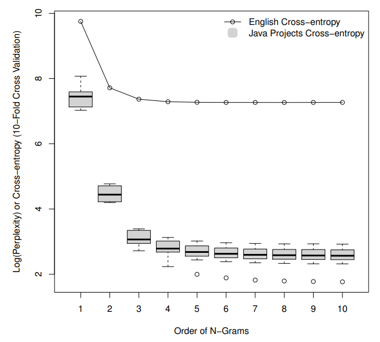
Hindle et al. On the naturalness of software. In ICSE 2012. https://doi.org/10.1109/ICSE.2012.6227135
ML/AI4SE Overview > Naturalize
Application of language models
- Predict and suggest coding conventions: identifier naming, whitespace, newlines
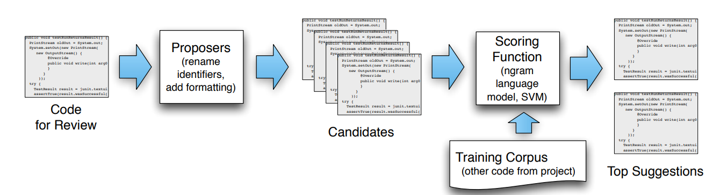
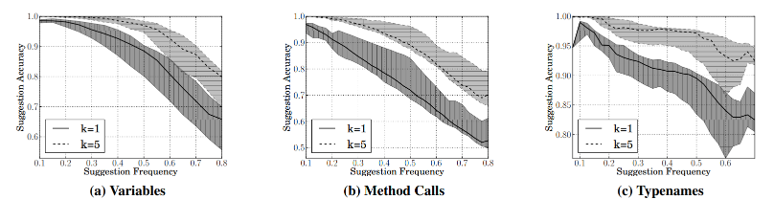
Allamanis et al. Learning natural coding conventions. In FSE 2014. https://doi.org/10.1145/2635868.2635883
ML/AI4SE Overview > Graph NGram
Unique property of code: structures
- Capture tree and graph structures of code, not just token sequences
- Still n-gram — just the graph version of it
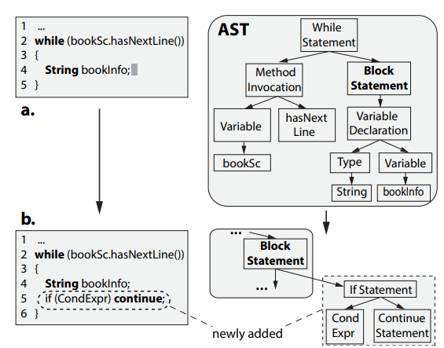
Nguyen and Nguyen. Graph-based statistical language model for code. In ICSE 2015. https://doi.org/10.1109/ICSE.2015.336
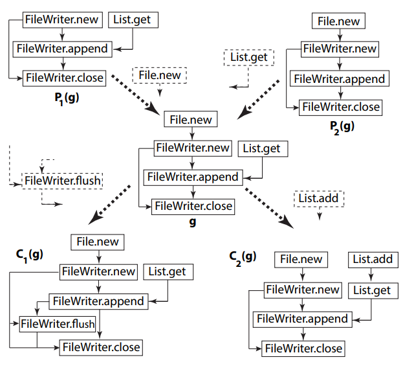
ML/AI4SE Overview > RNN, CNN
Neural language models for code
- From n-grams to neural sequence models
- RNNs for code ↔ text (e.g., API recommendation)
- CNNs with attention + copy mechanism for extreme code summarization
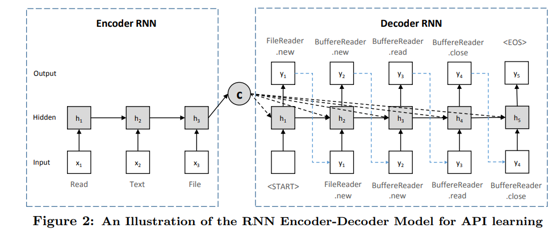
Gu et al. Deep API learning. In FSE 2016. https://doi.org/10.1145/2950290.2950334
Allamanis et al. A convolutional attention network for extreme summarization of source code. In ICML 2016. https://proceedings.mlr.press/v48/allamanis16.pdf
ML/AI4SE Overview > Grammar-based
Grammar-constrained code generation
- Constrain the output to be syntactically valid programs
- Text ↔ code translation becomes a popular task
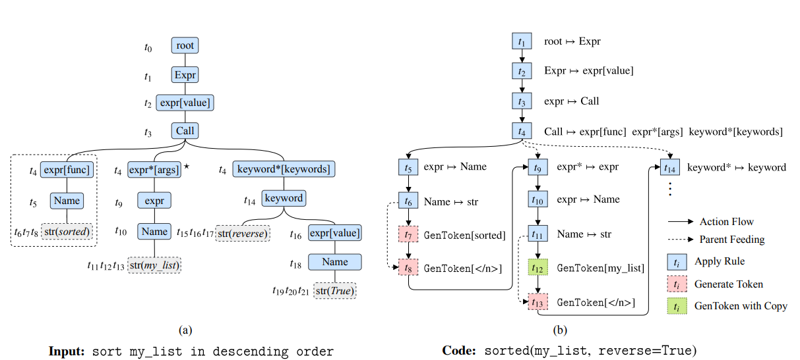
Yin and Neubig. A syntactic neural model for general-purpose code generation. In ACL 2017. https://arxiv.org/abs/1704.01696
ML/AI4SE Overview > Path-based
AST-path program representations
- Encode programs using paths through the abstract syntax tree
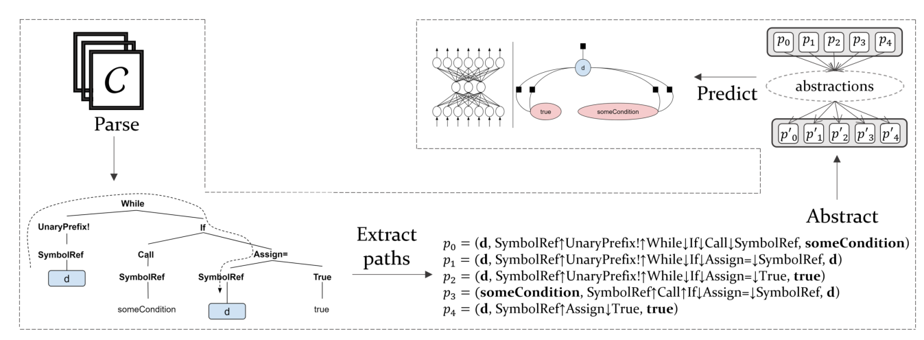
Alon et al. A general path-based representation for predicting program properties. In PLDI 2018. https://doi.org/10.1145/3192366.3192412
ML/AI4SE Overview > CodeSearchNet
Large-scale datasets
- Race of collecting massive, high-quality datasets/benchmarks for code
- CodeSearchNet: multi-language code search corpus (code and comment pairs)
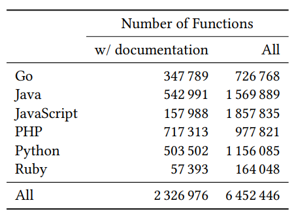
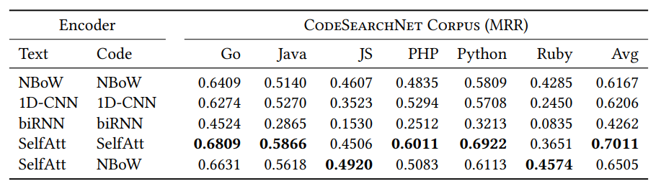
Husain et al. CodeSearchNet challenge: evaluating the state of semantic code search. 2019. https://arxiv.org/abs/1909.09436
ML/AI4SE Overview > CodeBERT
Transformers, pre-trained on large-scale datasets
- BERT-style encoder, trained on bimodal (code, NL) corpora
- Pre-training objectives specific to SE (MLM + replaced token detection)
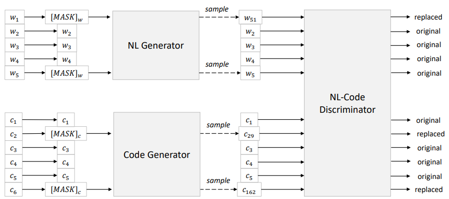
Feng et al. CodeBERT: a pre-trained model for programming and natural languages. In Findings of EMNLP 2020. https://arxiv.org/abs/2002.08155
ML/AI4SE Overview > CodeXGLUE
Transformers, multi-tasking
- CodeXGLUE: 14 tasks across 4 categories: code-code, code-text, text-code, text-text
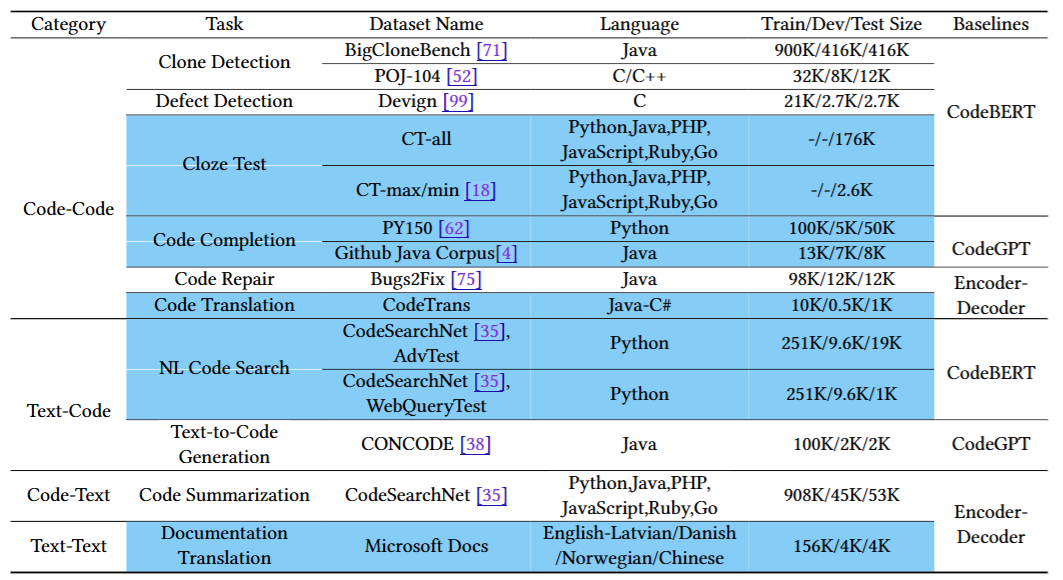
Lu et al. CodeXGLUE: a machine learning benchmark dataset for code understanding and generation. In NeurIPS Datasets and Benchmarks 2021. https://arxiv.org/abs/2102.04664
ML/AI4SE Overview > Codex
Scaling up -> Large Language Models
- GPT-3 fine-tuned on a large code corpus (later becomes GitHub Copilot)
- Introduced HumanEval, using test pass/fail as evaluation metric
- Scaling law of model accuracy and size
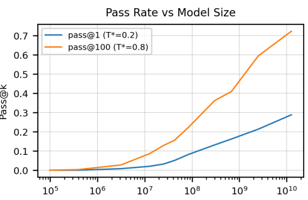
Chen et al. Evaluating large language models trained on code. 2021. https://arxiv.org/abs/2107.03374
ML/AI4SE Overview > StarCoder
Open-source code LLMs
- Open-source pre-training data (mined from GitHub) and LLM
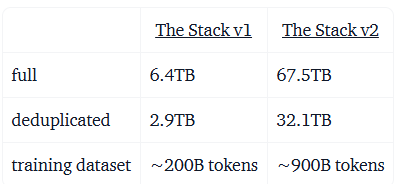
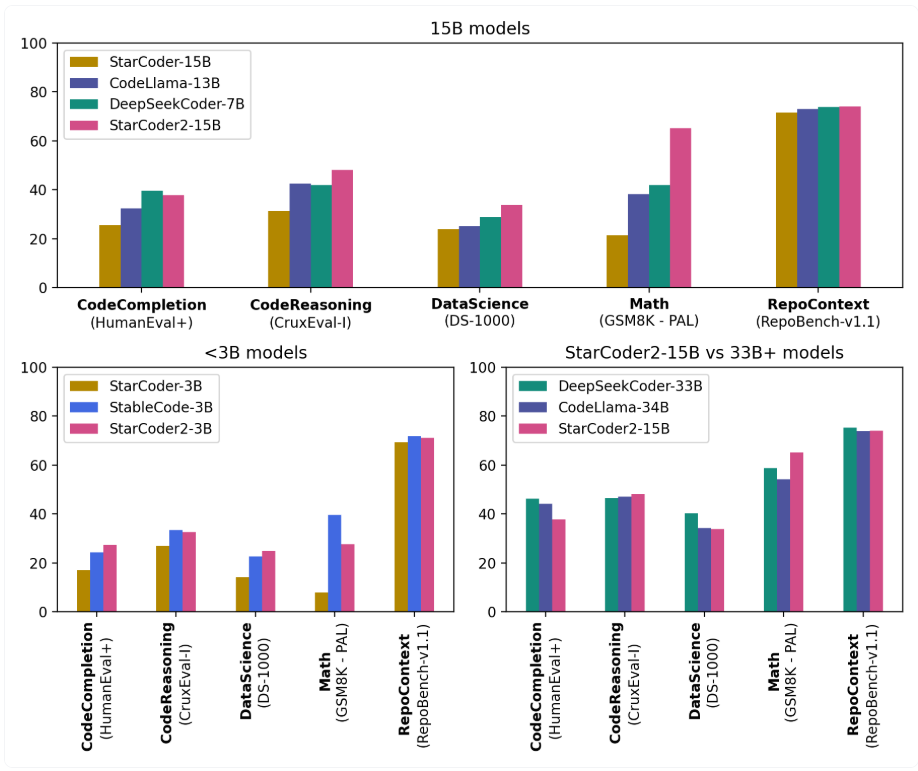
Li et al. StarCoder: may the source be with you! In TMLR 2023. https://arxiv.org/abs/2305.06161
von Werra et al. StarCoder2 and The Stack v2. https://huggingface.co/blog/starcoder2
ML/AI4SE Overview > SWE-Bench
More challenging benchmarks, matching real-world workflows
- Original SWE-bench: 2,294 issues from 12 popular Python repositories
- Follow-ups: SWE-bench Lite, Verified, Multimodal, Live, Multilingual, ...
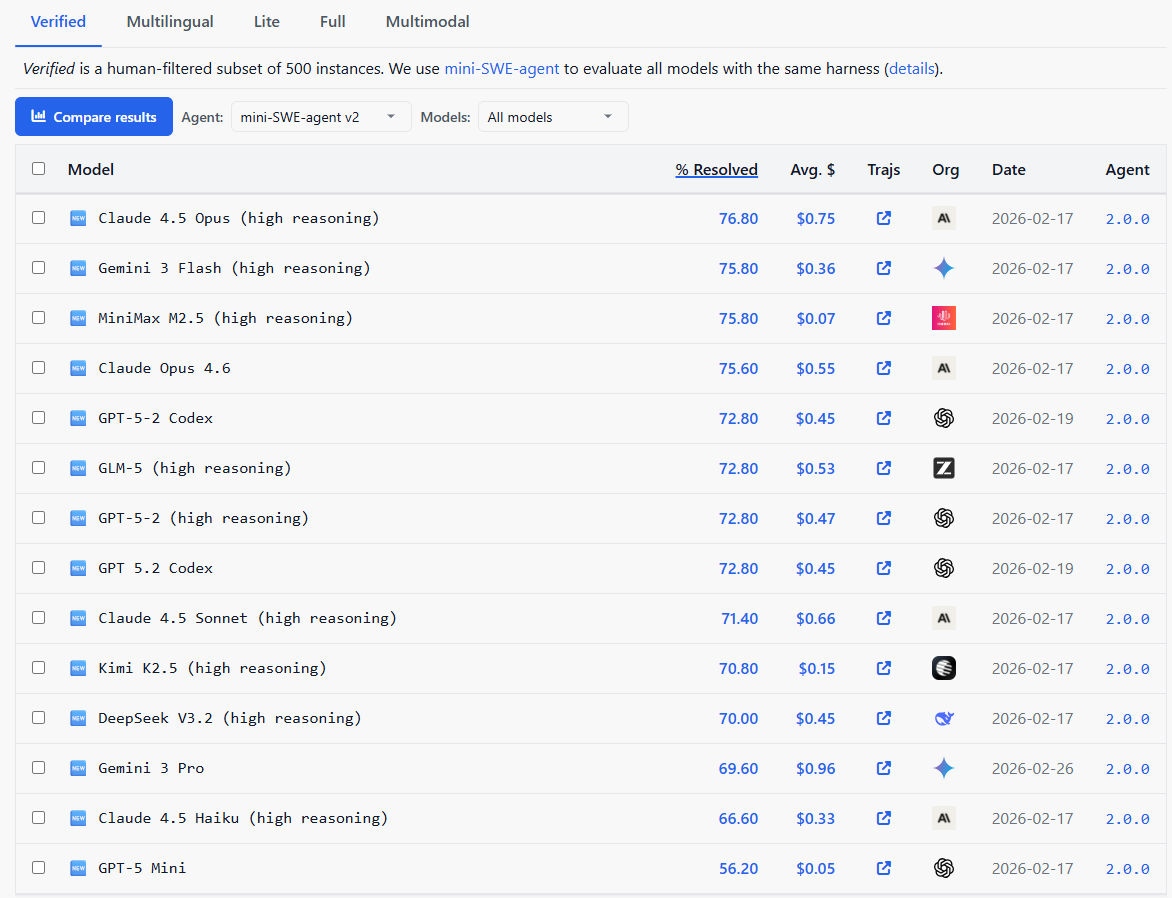
Jimenez et al. SWE-bench: can language models resolve real-world GitHub issues? In ICLR 2024. https://arxiv.org/abs/2310.06770; [SWE-bench leaderboard]
ML/AI4SE Overview > SWE-Agent
Single model -> agent
- Multiple rounds of input/output
- Repository-scale context, edits, reasoning, tool use, long-horizon tasks...

Yang et al. SWE-agent: agent-computer interfaces enable automated software engineering. In NeurIPS 2024. https://arxiv.org/abs/2405.15793; [latest version: mini-swe-agent]
ML/AI4SE Overview > SOTA
State of the Art as of 2026/05
- Strong code agents in production (and frontier of AI research in general)
- IDE style: Cursor, GitHub Copilot
- CLI style: Claude Code, Gemini CLI, Codex CLI
- They can automate many software engineering tasks, far beyond predicting next token
- They also produce many technical debts, hallucinations, security issues, …
- What’s next? What is the Future of Software Engineering?