Machine Learning Essentials
CS846 Machine Learning for Software Engineering — Spring 2026
Pengyu Nie
Agenda
- Goals
- ML4SE process: data processing, training, evaluation
- techniques
- language modeling, transformers
- fine-tuning (LoRA)
- decoding algorithms, agents
- No-Goals
- not too much internal working mechanisms (essentials as users of the techniques)
- ML/AI libraries and tools evolve very fast, you should research into what’s the latest
ML4SE Process Overview
- Task: input $x$, output $y$
- Dataset: $D = \{(x_i, y_i)\}$
- Model: training $M_\theta = \mathrm{train}(D_{train})$, inference $y = M_\theta(x)$
- Evaluation: $s = \mathrm{metric}(D_{test}, M_\theta) = \mathrm{Avg}(\mathrm{metric}(y_i, M_\theta(x_i)))$
Data Processing
- Data collection (mining software repository) sources:
- GitHub (open-source repositories)
- (raw) datasets mined in prior work
- Data cleaning filters:
- License permissive [ARR checklist] [NeurIPS checklist]
- Quality: #stars > x, not fork
- Recency: last commit > t, timestamp > t
- Correctness: build/compilation success, tests pass
- Task-specific concerns: input-output mapping, context, …
- quantity vs. quality
Model > Language Modeling Examples
Large language model
Predict the next token given a prefix:
- Once upon a …
import numpy as…static public void main ( String [ ] args )…
Identify unconventional and likely incorrect code (naturalness of software)
String userInput = new Scanner(System.in).next();String user_input = new Scanner(System.in).next();String userInput = new Scanner(System.out).next();
Model > Language Modeling Definition
- A language model computes either:
- probability of a whole sequence: $P(W) = P(w_1, w_2, \dots, w_T)$
- probability of the next token: $P(w_t \mid w_1, w_2, \dots, w_{t-1})$
- chain rule:
- $P(W) = \prod_{t=1}^{T} P(w_t \mid w_1, \dots, w_{t-1})$
Model > N-gram Language Model
statistical language model
- Markov assumption: condition only on the previous $n-1$ tokens:
- $P(w_t \mid w_1, \dots, w_{t-1}) \approx P(w_t \mid w_{t-n+1}, \dots, w_{t-1})$
- An n-gram is $n$ consecutive tokens; estimate the probabilities from token frequency:
- unigram ($n=1$): $P(w_t)$
- bigram ($n=2$): $P(w_t \mid w_{t-1}) = \dfrac{c(w_{t-1}, w_t)}{c(w_{t-1})}$
- special tokens:
<s>begin,</s>end of sequence
- Does not generalize beyond seen n-grams
Model > Perplexity
- The best language model is one that best predicts the corpus
- usually monitored on train/val sets
- Perplexity: inverse probability normalized by length (lower = better):
- $\mathrm{PP}(W) = P(w_1, \dots, w_T)^{-\frac{1}{T}}$
- Equivalently, the exponential of the cross-entropy
- $H(W) = -\frac{1}{T} \sum_{t} \log P(w_t \mid w_{\lt t})$.
- usually used as the loss function for training the language model
Model > Transformer
(decoder-only) transformer architecture
- The state-of-the-art language model
- neural network: generalizability, scalability
- evolution: RNN -> attention layer -> ~
- Key component: self-attention layer
- Typical sizes: ~1B, ~4B, ~7B, ~13B, ~70B, ~300B
Image modified from Vaswani et al. Attention is all you need. In NeurIPS 2017. https://arxiv.org/abs/1706.03762
Model > Transformer > Self-Attention

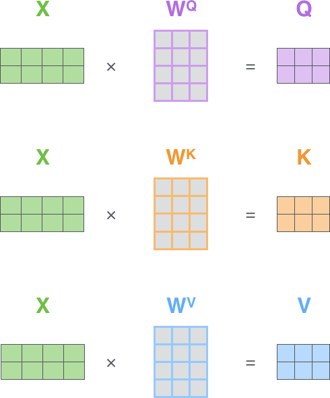
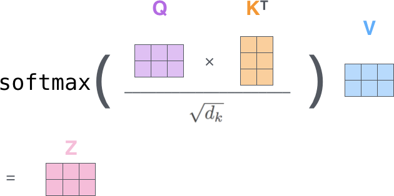
- Input X = embeddings from prev layer
- Query: the token currently asking
- Key: the token being compared against
- Value: the information to aggregate
- Output Z = embeddings to next layer
(re-weighted with context similarity)
Model > Transformer > Architecture Variants
encoder vs. decoder
- decoder-only: standard (thanks to scalability); GPT, Llama, Qwen
- encoder-only: good for embedding/classification; BERT
- encoder-decoder: the original architecture, good for input-output mapping; BART, T5
bottleneck: speed up $\mathcal{O}(n^2)$ attention computation
- [Flash Attention], IO-aware exact attention
- KV cache: reuse past keys/values when decoding instead of recomputing
Mixture of Experts (MoE): route each token to a few expert sub-networks, more parameters at similar inference-time cost [Mixtral]
Speculative decoding: a small draft model proposes next few tokens, the large model verifies them (faster) [Leviathan et al. 2022]
Model > Tokenization
How (L)LM tokenize natural language and code?
- Used to be:
- whitespace-based / regex
- unseen tokens =
<UNK> - (for code) CamelCase/snake_case sub-tokenization
- Data-driven approach: learn the best way to tokenize
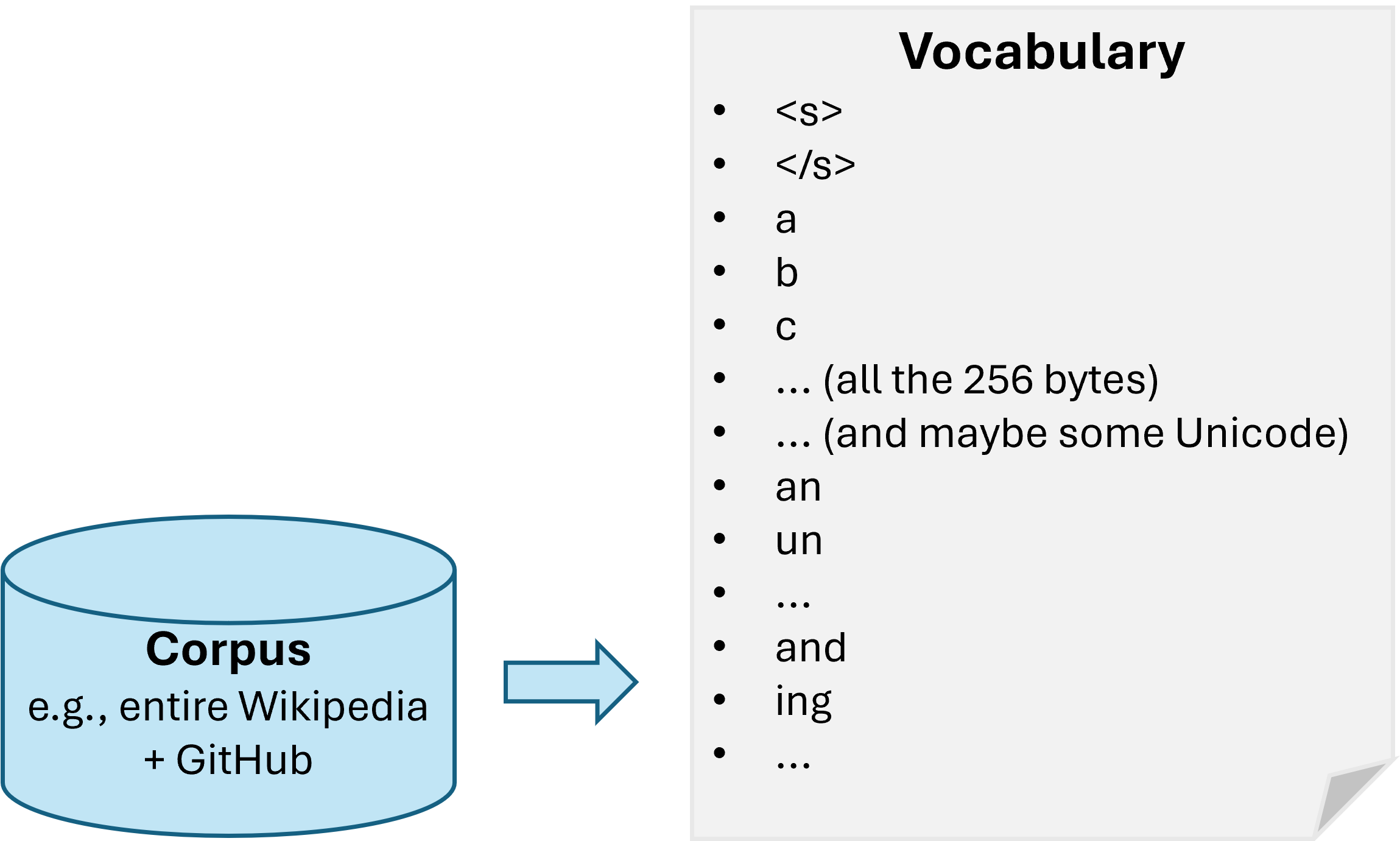
- Byte-pair encoding (BPE) algorithm
- initialize vocabulary with base tokens (all bytes)
- while |vocabulary| < v:
- find the most frequent adjacent token pair in the corpus
- merge it into a new token and add to the vocabulary
Model Training
Training of an LLM has many phases:
| Phase | Goal | Data | Strategy |
|---|---|---|---|
| pre-training | learn generic knowledge | massive raw (unlabelled) corpus | semi-supervised learning (language modeling) |
| mid/post-training | improve reasoning | math, code, NL reasoning | supervised learning + reinforcement learning |
| ~ | improve tool use / agent | data with tool use traces | ~ |
| ~ | improve instruction following | data with human labels | reinforcement learning (RLHF) |
| fine-tuning | apply to task | task-specific data | parameter-efficient fine-tuning (PEFT, e.g., LoRA) |
Model Training > LoRA Fine-tuning
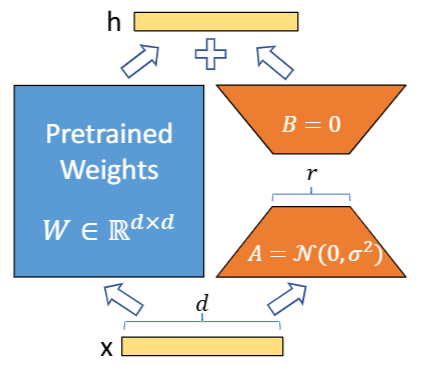
- Full fine-tuning (FFT) updates all weights $W$ and stores a full model copy per task
- Parameter-efficient fine-tuning (PEFT): freeze $W$, only update a few parameters $\Delta W$
- LoRA [Hu et al. 2021]
- $\Delta W = BA$ with rank $r \ll d$:
- $h = Wx + \Delta W x = Wx + \tfrac{\alpha}{r}\, B A x$
- Only $B \in \mathbb{R}^{d \times r}$ and $A \in \mathbb{R}^{r \times d}$ are trained
(usually 1-10% of the model size)
Model Inference
- Prompt engineering
- Decoding algorithms: greedy, sampling
- Test-time scaling: “learning” without updating model parameters:
- in-context learning, few-shot learning
- retrieval-augmented generation (RAG)
- chain-of-thought (CoT)
- self-consistency
- Agentic harness (e.g., [mini-SWE-agent])
Model Inference > Greedy Decoding
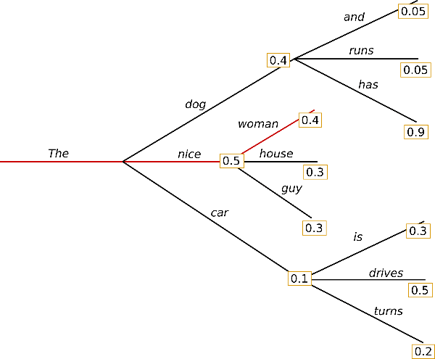
Greedy decoding
- Pick the highest-probability token at each step
- $w_t = \arg\max_{w} P(w \mid w_{\lt t})$
- Deterministic (theoretically) given the same input
- Locally optimal ≠ globally optimal; can miss higher-probability sequences and become repetitive
Image from https://huggingface.co/blog/how-to-generate
Model Inference > Sampling Decoding
Sampling decoding (aka top-k/top-p/Nucleus sampling)
- Sample the next token randomly from output distribution $P(w \mid w_{\lt t})$
- more diverse, human-like output
- Restrict the candidate set: top-k (k most likely) or top-p (smallest set with cumulative probability $\ge p$)
- Temperature controls randomness: $p_i = \dfrac{\exp(o_i / T)}{\sum_j \exp(o_j / T)}$
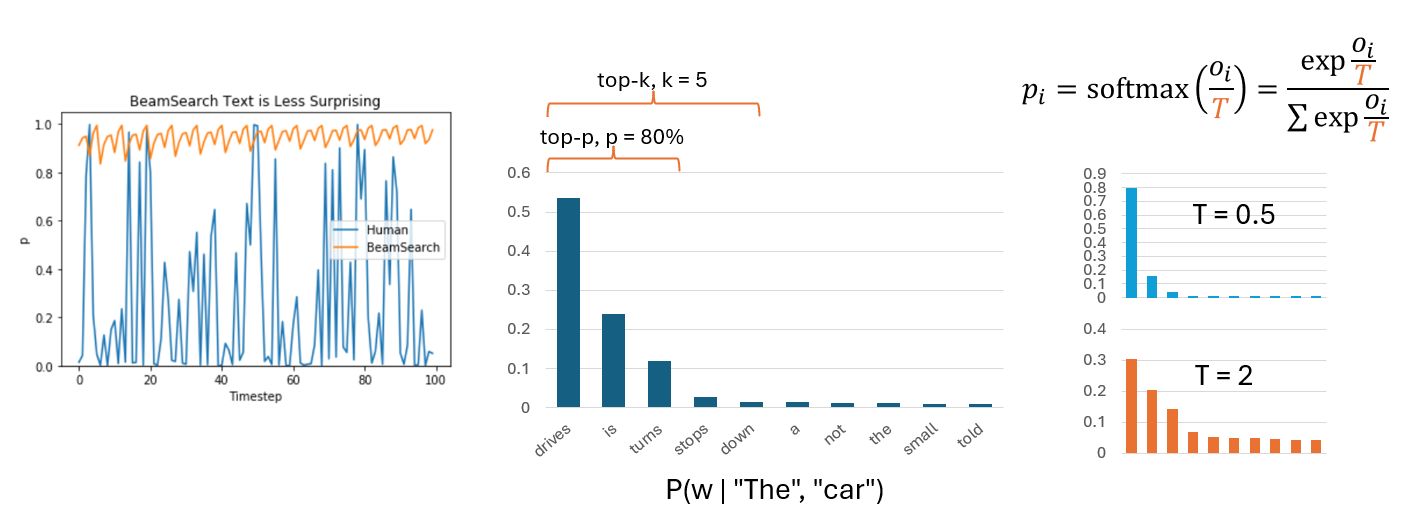
Image from https://huggingface.co/blog/how-to-generate
Evaluation > Data Split
- Train/val/test splits
- Validation (aka development) set: make design decisions, early-stop training
- Test set: held-out for final evaluation
- It is wrong to make design decisions based on test set performance
- Prevent data leakage
- The model will be eventually deployed to production data
- can be partially or completely unseen -> cross-project split
- most likely future data -> time-segmented split
- For evaluation scores to match production performance:
$D_{test}:(D_{train}+D_{val}) \approx D_{production}:(D_{train}+D_{val}+D_{test})$ - For making correct design decisions:
$D_{val}:D_{train} \approx D_{test}:(D_{train}+D_{val})$
- The model will be eventually deployed to production data
Evaluation > Metrics
- Similarity-based metrics: Exact match, BLEU, CodeBLEU, F1, …
- require ground truth (developer-written $y$)
- may not be the only correct answer
- may be wrong (related to data processing quality)
- lack “semantic” understanding; one workaround: embedding similarity
- require ground truth (developer-written $y$)
- Execution-based metrics: build success rate, test pass rate (Pass@k), coverage, …
- some require executable artifacts (tests)
- may need appropriate hardware/OS environment
- may be wrong
- not applicable to natural language artifacts (comments)
- some require executable artifacts (tests)
- Human validation [related online guideline]
- cost vs. benefit: case study, statistically sampled subset
- measure inter-rater agreement (e.g., Cohen’s Kappa)
- Can LLM replace human validators? [Ahmed et al. 2024]
Evaluation > Variance Control
- Model training and inference are stochastic processes
- can be partially controlled by setting random seeds
- but hard to rule out all the hardware/library effects (greedy decoding can even be stochastic!)
- Repeat experiment k (usually=3/5) times
- use different random seeds
- report average score
- perform statistical significance testing to compare between methods